SEO for large websites
How does SEO change on large/enterprise websites? And how can we do it well?
It's a big topic and I'm not even going to try and cover everything in this blog post (or the presentation it was written for).
Instead we're going to focus on two main areas.
- Working with data
- Technical SEO foundation
Hopefully the other ones will be covered in future blog posts/presentations!
Slides
If you saw the presentation and want to jog your memory, here are the slides.
What will we cover?
If you missed presentation, or fancy skipping the Gorilla jokes then I've got a written version.
We're going to cover 4 topics:
-
Templates
- If you're working on big sites, you need a template sheet.
-
Getting & Processing Data
- The larger the site the harder it is to work with the data. We have to do more work than normal.
-
Finding Technical Issues
- Big sites need more prioritizing and are harder to work with.
-
Preventing Technical Issues
- It's hard to keep track of large sites/large numbers of sites. Prevention is always better than the cure.
Templates
Website are built on templates, category pages, product pages etc.
When you have a problem with a template it gets applied to every page in the template and because of that it's usually all the largest issues.
When sites get large we can lean on templates to reduce the scope of what we have to check.
Make a template sheet
Have you got a list of all the templates for your site to hand? Time to get one.
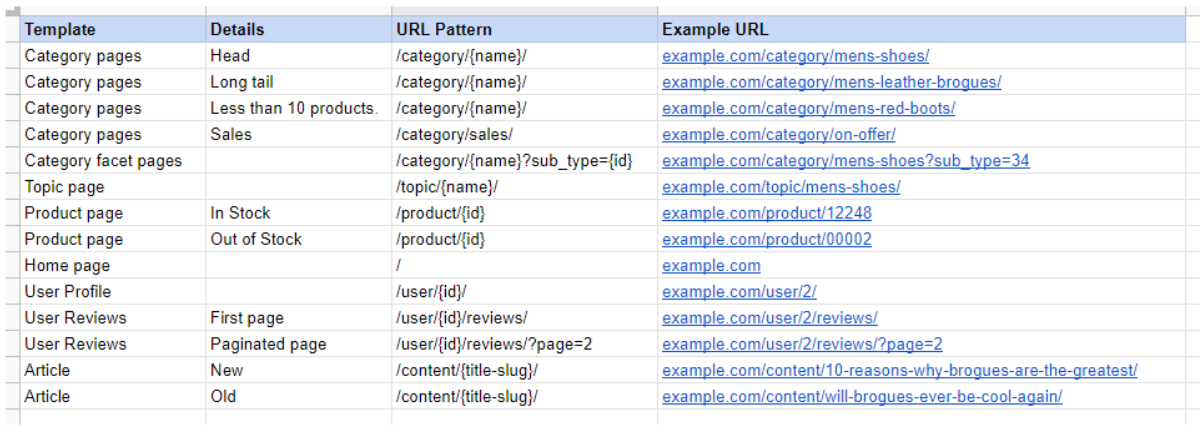
Make a list of every different template on your website along with example URLs.
We'll put in the obvious templates, things like:
- Category template
- Article template
- Product page template
- etc.
Then we'll start adding more variants.
A template is really just some logic and rules to build a webpage. We can spot them visually, but we can also guess variants of templates, or different states and we should record those too.
- Category template with less than 5 products.
- Product template in stock.
- Product template out of stock.
- Blog with no author
- Blog with author
- etc.
We should also look for variants of URLs
- Category template with parameters from sorting
- Facetted category page
And location levels:
- City level location page
- Street level location page
We can cut down our millions of URLs to a more manageable list of templates and variants. It's typically hard to get everything, but aim for the 90/10 rule.
An example template sheet
Here's an example template for your templates sheet to get you started!
Getting and processing data
Great we've got our templates. Now we actually need to work with the site.
The first problem you'll typically bump into is working with the data. It was easy on small sites.
Now you'll bump into all sorts of problems.
- Google analytics keeps sampling.
- You'll hit a data limit in a spreadsheet.
- Even before you hit the data limits, everything is super slow.
- The data you need is segmented and split across multiple sources and those are all slow!
How can we get as much data as possible, without sampling and without everything slowing to a crawl?
What do we need to do?
Broadly we need to be able to do four things:
- Get the data
- Store the data
- Analyze the data
- Report on the data.
Getting data at scale
Depending on the data source the methods we can use change a lot.
For this post I'm going to focus on quick tips for the most common data sources (i.e. Google ones), I'll make follow-up posts for more specialised ones like Adobe.
Get it all from data studio
For Google sources you can make tables in Data Studio for whatever data you want and just download them from there.
Data sources will still sample, but you will get around Search Console 1000 row limits, or pagination in Google Analytics.
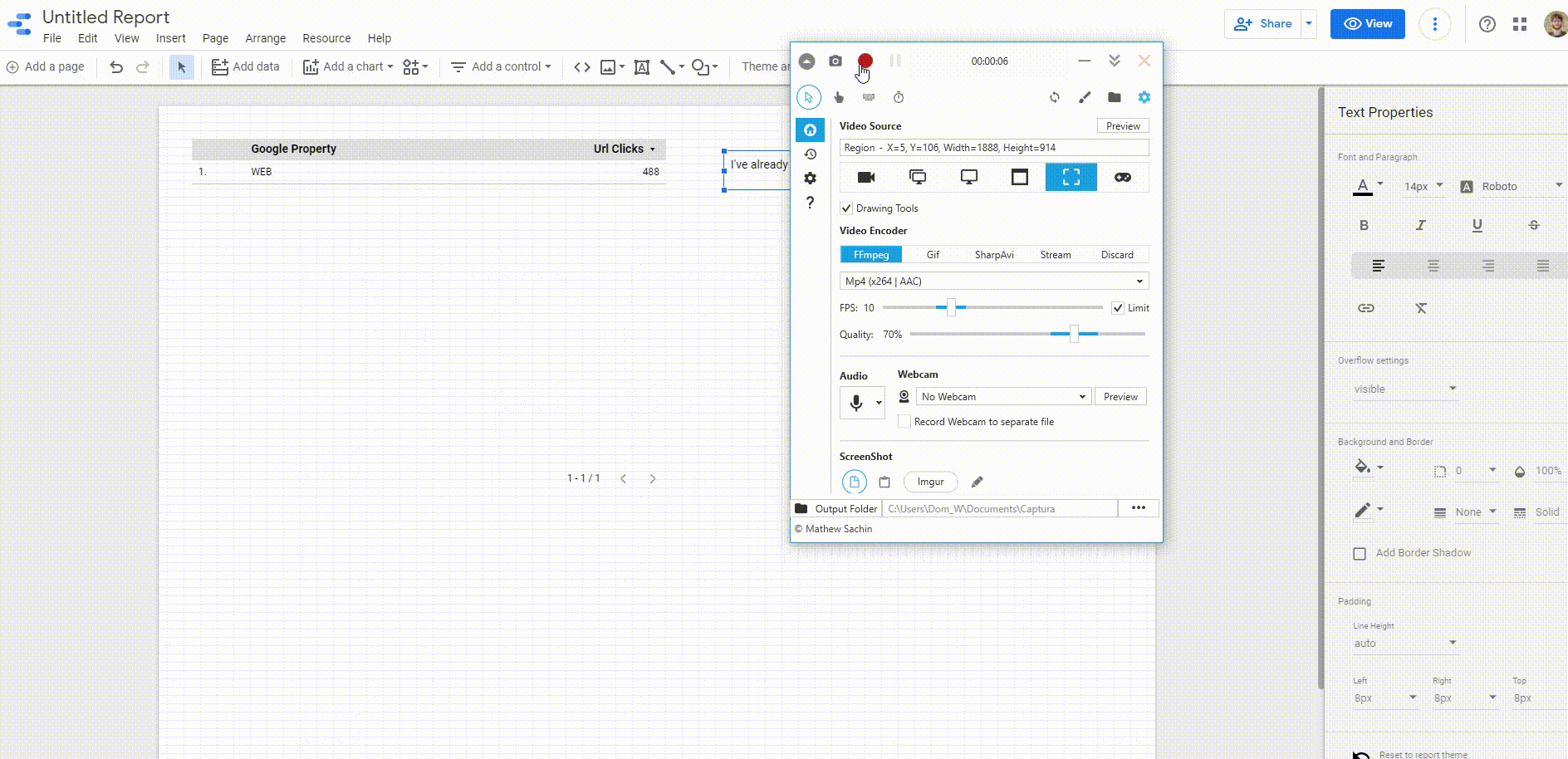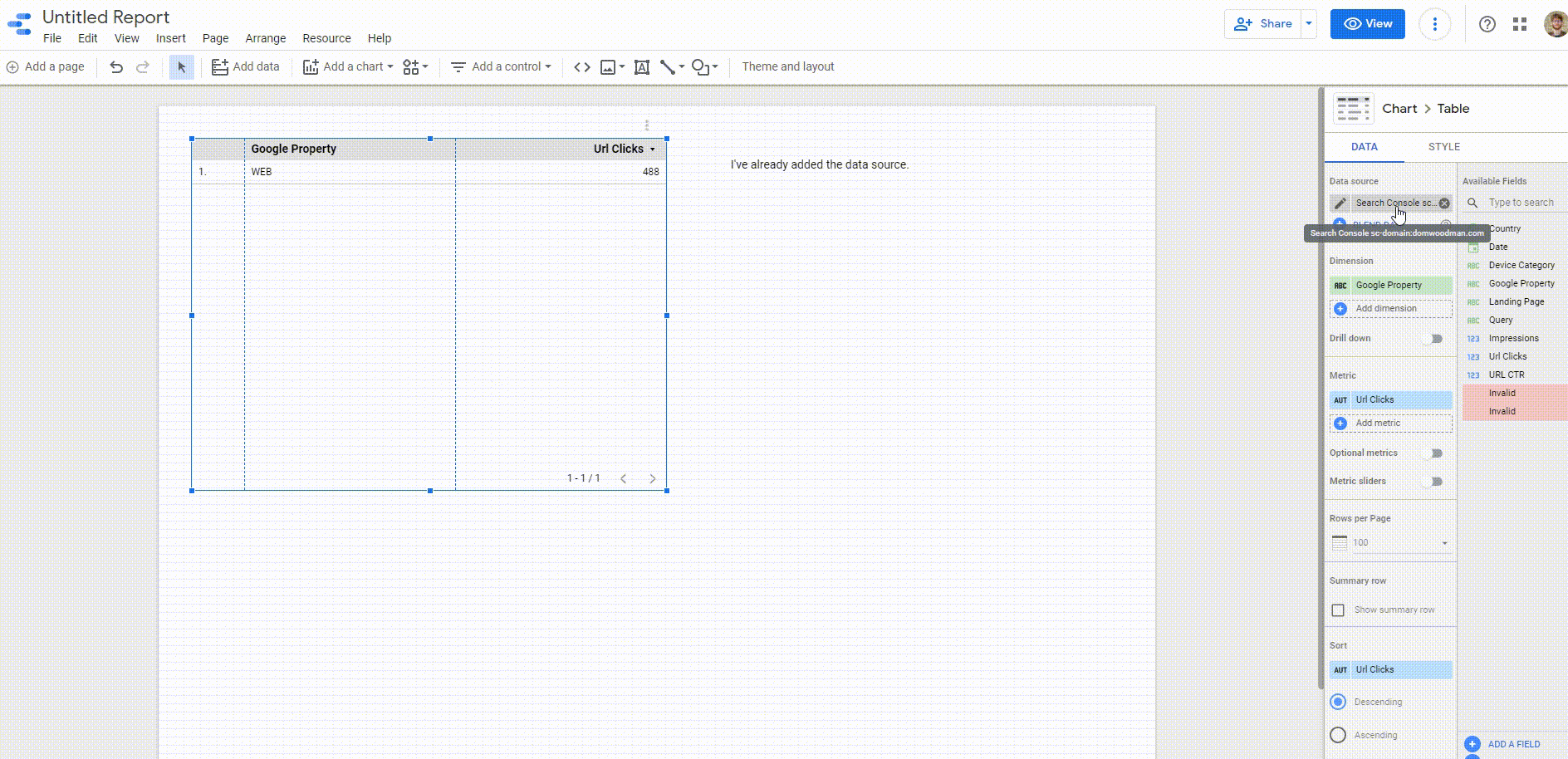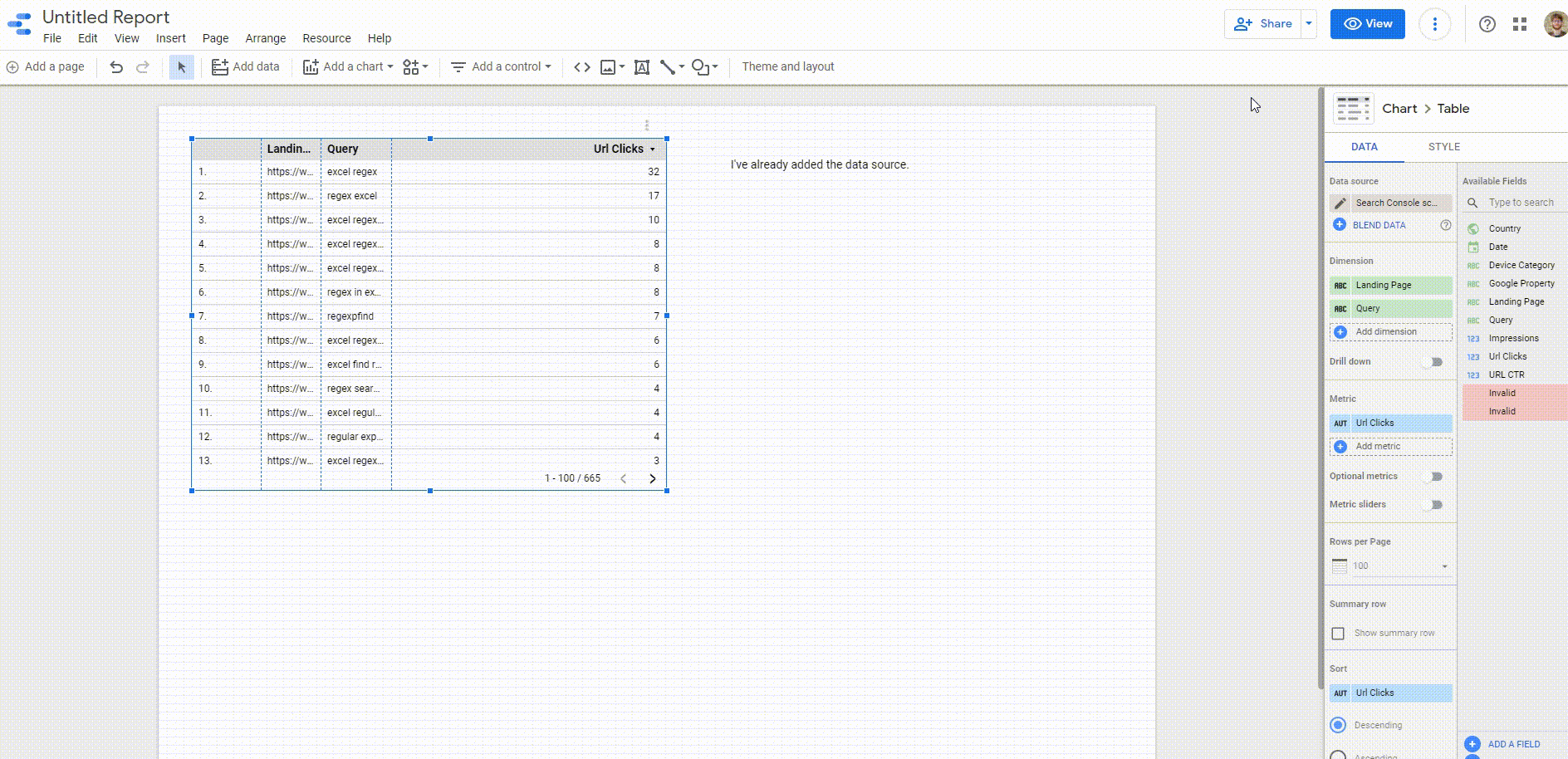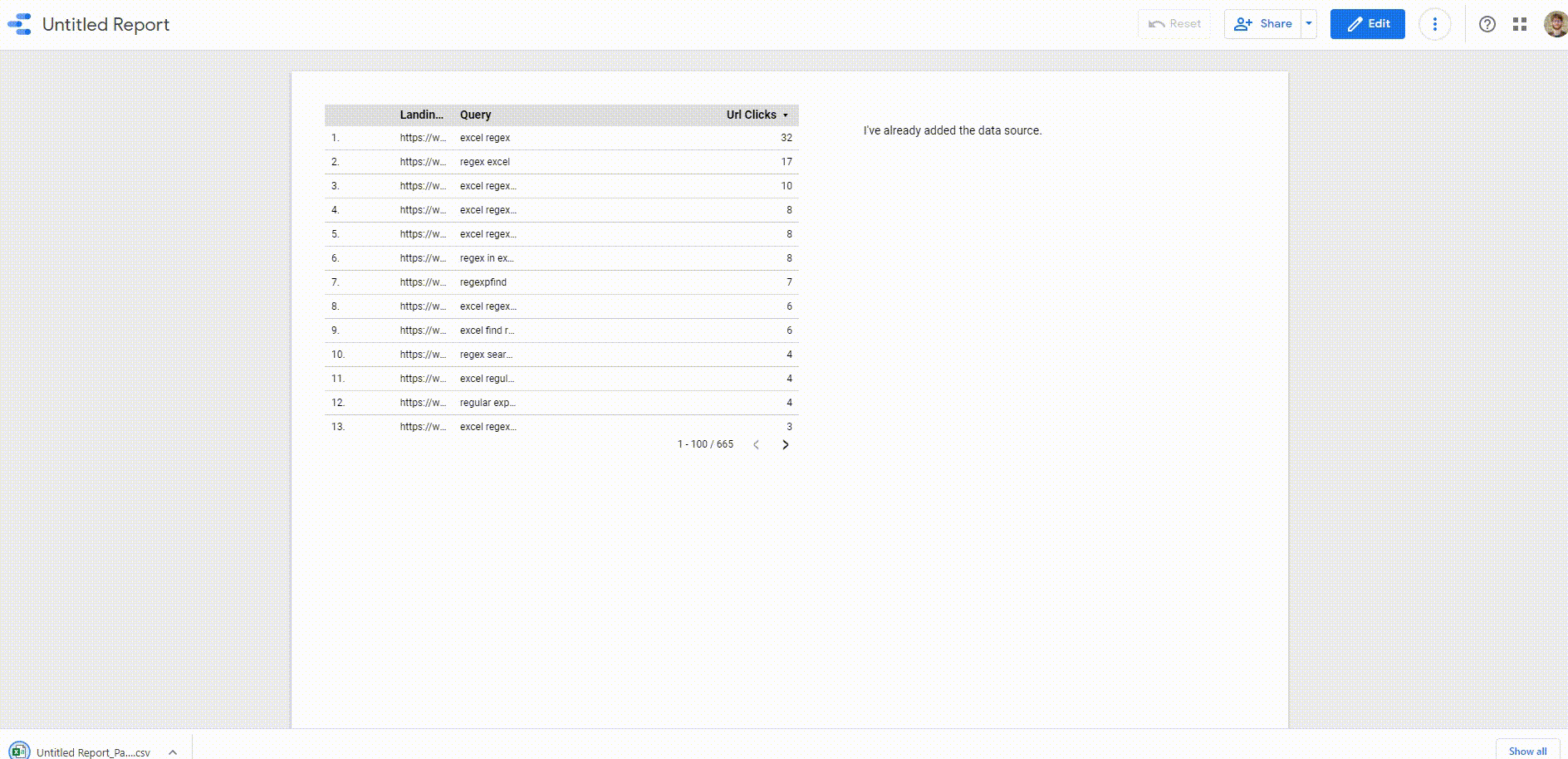
You need to:
- Make a DS report
- Use the DS connector to create the table
- Download.
Use a Google sheets integration
Again for certain data sources there may be a free Google sheets integration.
- Google Analytics: https://developers.google.com/analytics/solutions/google-analytics-spreadsheet-add-on
- Google Ads: https://support.google.com/google-ads/answer/9000139?hl=en-GB
You'll still sample, but you get to avoid some of the complexities.
Web tools
The easiest way to avoid sampling is to get all your data, day by day.
-
Search Console: I made a tool over on Piped Out, that you can use to download all of your Search Console data day by day.
- Warning: This is genuinely a lot of data if you have a big site...
Download it with python
We're about to come onto python, but to skip ahead. Python can be used to get all the data.
Here are a handful of scripts I've used to download data day by day to avoid sampling & maximize the amount of data.
Analyzing the data
For big data spreadsheets start to lack power.
To really dig in you're either going to need to know SQL to work with a data warehouse or python to analyze at scale.
Python
If you're going to consistently work on large sites, learning python will absolutely benefit you.
This isn't something you should take on lightly - it's a lot of effort.
If you work day to day on large sites and see yourself continuing on this path, then it's super valuable. If you're not sure that working on large sites is for you, then I definitely wouldn't learn this first.
Do you need convincing allow me to handover to an ex-colleague - Robin Lord:
The video is paid, but if you can grab a license from your company, I cannot recommend this talk enough.
Useful resources for python
Otherwise I'll point off to handful of other useful resources:
- Code Academy Python: The code academy python course is an excellent starting point if you've never coded before.
- General guide to python for SEO: JC Chouinard has written an excellent series on using python for SEO. It's aimed at beginners and very useful.
- Pandas Tutorial: I made this pandas basic tutorial, which walks you through the basics of using pandas to replace Excel.
- Examples of scripts: SEO Pythonistas contains much of the late, very lovely Hamlet Batista's work. It's not super beginner friendly, but if you're looking for use cases or more complex things it's good.
Storing and reporting
For smaller sites spreadsheets do the storage, analysis and reporting.
When we scale up, we need different pieces of software to do those jobs.
For storage (& to make reporting easy) you're going to want a data warehouse.
- Good news: If you're a big company, you probably have one.
- Bad news: SEO data probably isn't in it. You'll need to work with your developers to get it loaded.
Back up for a second:
What is a data warehouse?
It's a place to store all your data... Imagine a series of colossal Excel spreadsheets in the cloud.
Here are a handful of screenshots of a very basic SEO data warehouse in BigQuery to help you picture it.
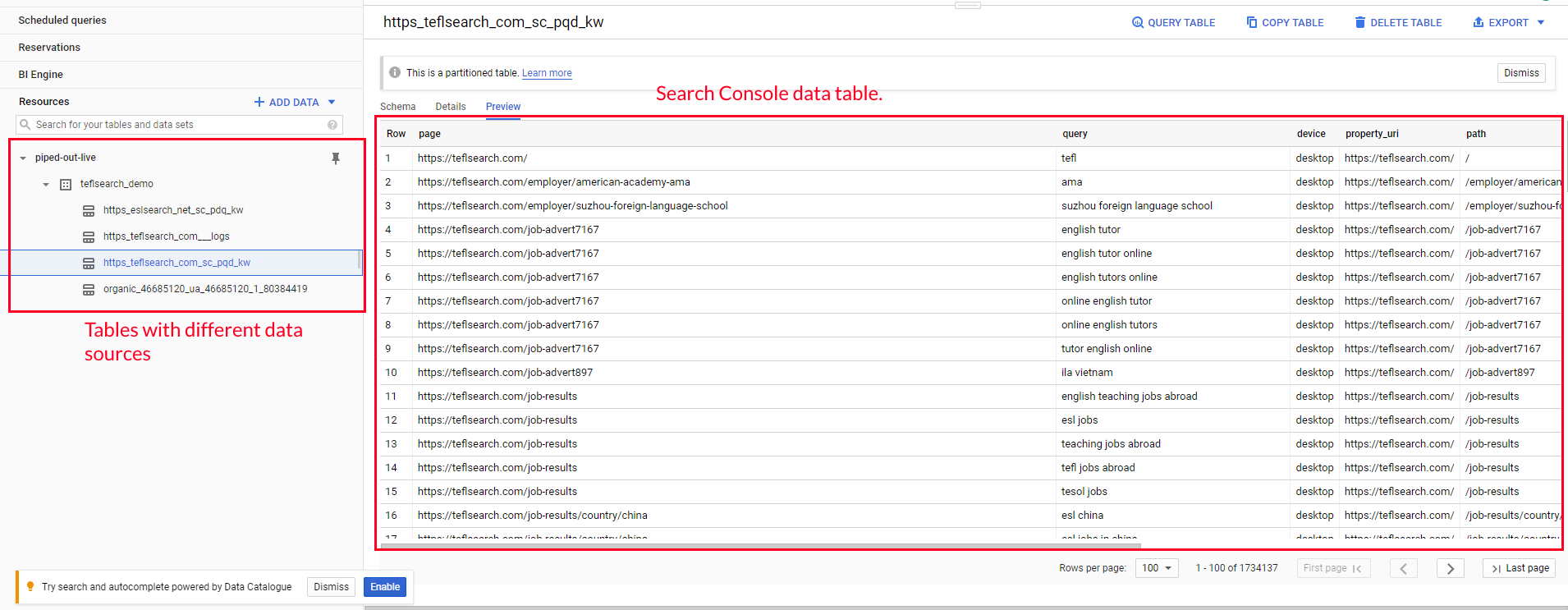
Why do we want one?
Because the data so large. I've got the SEO data for a large e-commerce data warehouse sitting in front of me and they're storing ~70GB of data for the past year.
And they have it all without sampling & slowing down.
On data warehousing scale, that's pretty small. On spreadsheet scale, that's monstrous. It's far too big to use as is on your computer
If you've ever used Tableau, Power BI, or even Data Studio at a large company there is a good chance it was using data from a data warehouse.
How do we use it?
We load all our SEO data into it and then we use one of the following to interact with it:
- SQL
- Python
- Front-end reporting tool
What are the next steps?
Time to go and talk to your dev team about getting SEO data loaded into it.
You've got the expertise about SEO data, they've got the knowledge of how your data warehouse works.
If you want external help, then I run Piped Out. We help SEO teams get data warehouses and make them easy to work with.
Finding technical problems
We all roughly know how to find technical issues, there are two big steps:
- Find errors
- Prioritize
The first we usually do with crawling. The second varies a lot per SEO, but typically some version of gut instinct/traffic numbers etc.
Finding errors - crawling small
The main issue with finding issues, is crawling everything.
How do we get around it?
We take our template sheet and just crawl that.
We're not going to catch everything (e.g. broken links on articles), but we will catch any obvious templated issues.
It's so small we can even crawl it every day.
Finding Errors - crawling large
Every now and again you probably will need to crawl large. You need to look for unknown unknowns and by definition your sheet probably doesn't have those.
What do we do then?
Restrict the crawl
Actually we still try to avoid crawling large.
DeepCrawl has an excellent feature which allows you to restrict a percentage of your crawl per template. i.e. only 20% of your crawl should be product pages.
This is a brilliant way to uncover unknown unknowns on large sites.
Use a low memory crawler
Another ex-colleague Ben Estes made this useful low memory crawler.
It doesn't run JS or do much pre-processing, but for specific use cases (i.e. running a giant crawl ) it's excellent.
Crawl in the cloud
Running SF or Sitebulb in the cloud.
Most of the guides rely heavily on the CLI, SEMPioneer has a reasonably beginner post friendly on setting up cloud crawling (well about as basic as you'll get for this sort of task.)
Prioritizing issues
The big problem with the templated approach is prioritizing.
Spotting a problem on one template, doesn't necessarily tell you how important it is (you know unless you no-indexed all your product pages...)
For prioritizing we're going to use a combination traffic/revenue/log files.
Using traffic/revenue we can measure how important our pages are to us. With log files, we can see what Google is spending it's time on.
We'll use that to build our an impact/effort prioritization.
Log files - A quick side bar
This part will eventually become it's own post. Log files are useful enough that I want to highlight a couple things here.
What are log files good for?
- Crawling & indexing problems
- Measuring freshness
- Prioritisation
- Monitoring website changes (e.g. migrations)
- Debugging
Why are log files particularly good on large sites?
1, 3 & 4 are all notably harder/more important on large websites and log files Excel at them.
A quick example below:
An email to get started
This is a copy of email which I'll usually send some version of at the start of a log project. It covers a lot of caveats and is a good place to get started.
Hi x,
I’m {x} from {y} and we’ve been asked to do some log analysis to understand better how Google is behaving on the website and I was hoping you could help with some questions about the log set-up (as well as with getting the logs!).
What time period do we want? What we’d ideally like is 3-6 months of historical logs for the website. Our goal is to look at all the different pages search engines are crawling on our website, discover where they’re spending their time, the status code errors they’re finding etc.
We can absolutely do analysis with a month or so (we've even done it with just a week or two), but it means we lose historical context and obviously we're more likely to lose things on a larger side.
There are also some things that are really helpful for us to know when getting logs.
Do the logs have any personal information in? We’re just concerned about the various search crawler bots like Google and Bing, we don’t need any logs from users, so any logs with emails, or telephone numbers etc. can be removed.
Can we get logs from as close to the edge as possible? It's pretty likely you've got a couple different layers of your network that might log. Ideally we want those from as close to the edge as possible. This prevents a couple issues:
- If you've got caching going on, like a CDN or Varnish then if we get logs from after them, we won't see any of the requests they answer.
- If you've got a load balancer distributing to several servers sometimes the external IP gets lost (perhaps X-Forwarded-For isn't working), which we need to verify Googlebot or we accidentally only get logs from a couple servers.
Are there any sub parts of your site which log to a different place? Have you got anything like an embedded Wordpress blog which logs to a different location? If so then we’ll need those logs as well. (Although of course if you're sending us CDN logs this won't matter.)
How do you log hostname and protocol? It's very helpful for us to be able to see hostname & protocol. How do you distinguish those in the log files?
Do you log HTTP & HTTPS to separate files? Do you log hostname at all?
This is one of the problems that's often solved by getting logs closer to the edge, as while many servers won't give you those by default, load balancers and CDN's often will.
Where would we like the logs? In an ideal world, they would be files in an S3 bucket and we can draw them down from there. If possible, we'd also ask that multiple files aren't zipped together for upload, because that makes processing harder. (No problem with compressed logs just, just zipping multiple log files into a single archive).
Is there anything else we should know?
Best, {x}
What do you do with logs when you've got them?
- You load them into your data warehouse.
- You analyze them.
I'm due to write an update for this, but in the meantime I've got an older post where I talk through the basics of log analysis.
Preventing technical issues
Right next on our whistle-stop tour is preventing issues.
If you manage a large site or lots of sites, you'll know how hard it is to keep track of everything. Death by 1000 tiny SEO cuts.
What are our options:
Change detection
Knowing something has changed is our first option.
First a shoutout to Robin Lord again for this excellent Google sheet for comparing SF crawls. You paste in two SF crawls and it will tell you what has changed.
And because we're crawling our template sheet, our entire browser won't crash.
Second shout-out goes to Little Warden. It checks a tonne of little things, which you'll forget until someone screws them up and you'll be glad you pay for it.
What is the correct value?
Knowing it's changed is useful, but to fix a problem you need to know what the correct value is.
One better than change detection is to check if a value is correct. e.g.:
- Page: example.com/blue-t-shirts
- Correct Title: Blue T-Shirts for Sale | Example.com
There's a blog post over on Piped Out with a Google Sheet which will let you do that - DIY Unit testing for SEO.
CI tests
Both of the above are great, but you're still catching tests when they're on live.
Ideally they'd be caught before the bugs go live and that means CI tests (you might have also heard unit test & integration tests being used, for our purposes they're interchangeable).
These are similar to the tests we described above, but rather than running them in a Google sheet, developers build these checks.
Then every time code is deployed the checks are run and if they fail, code doesn't go live.
There is unfortunately no easy way to get these. If you happen to be lucky enough to have something like Endtest, then it is possible, but picking a platform like that is a large decision which you'll have little say in.
If you don't have it, then you're going to have to work with your developers.
Conclusions
We've covered a lot of the obvious bits.
Broadly I think my approach to working on large websites is two fold:
- Set yourself up to work with large data.
- Wherever possible try to avoid it.
And you will have to, but by avoiding where you can you'll get more time to focus on data wrangling where it matters.
