Traffic Light SEO
Traffic Light SEO
Traffic Light SEO, is a chrome extension, designed to show you a page's indexation and meta data passively as you are browsing around the internet. You can download the extension here.
What is the point of this extension?
There are two common questions I often find myself wondering as a consultant and browsing around a clients site:
- Is this page indexed?
- What would this page look like in Google?
Both questions are quite time consuming to answer for any one particular page and so this extension will answer the questions for you and do it as you are browsing around.
{{< alert info >}} In order to check if a page is indexable, you have to look at the headers for canonical and no-index directives, the body for canonical and no-index directives and check the robots.txt file for a website. {{< /alert >}}
For those of you who are newer to SEO and are wondering why is knowing these are helpful:
- Particularly on large sites with lots of pages and templates, it's easy to create crawl problems and leave a site with Panda style issues where the vast majority of indexed pages are low quality.
- Seeing what the title and meta look like in Google, gives me a better idea of how clickable it is, as well as giving me an idea of what the page is targeting.
How does this extension work?
If you don't like using things you don't understand or have a healthy professional curiosity, then it might be useful for you to understand how this extension works.
Most important things to know
- This extension pulls from the rendered page, as rendered by Chrome. As you have read, Google does not treat all JavaScript equally, this means in the case of JS frameworks like Angular 2, where Chrome will render them, but Google will struggle this extension may give misleading answers.
- This extension downloads robots.txt as it browses and stores them in local storage. This cache can be flushed in the menu and is also flushed when the browser is closed. But this does mean it's possible to encounter a scenario where a website updates it's robots.txt after you've first visited it and before the cache is flushed. The extension has no way to know this has happened at the moment.
- The overall status of page indexation shows whether or not the page is currently indexable. For example if a page is blocked in robots.txt it will for example state this page is not-indexable, even though it could already be in the index and blocking it in robots.txt will not change that.
- The overall status of page indexation chooses to be generally useful rather than technically correct.... (What, outrageous!) If a page is blocked in robots.txt, that page is still indexable if someone else chooses to link to it. You'll get the Google result showing this content is not accessible due to robots.txt. But while this is technically correct the vast majority of robots.txt usage is for when you're using it to block access to worthless templates which will never be linked.
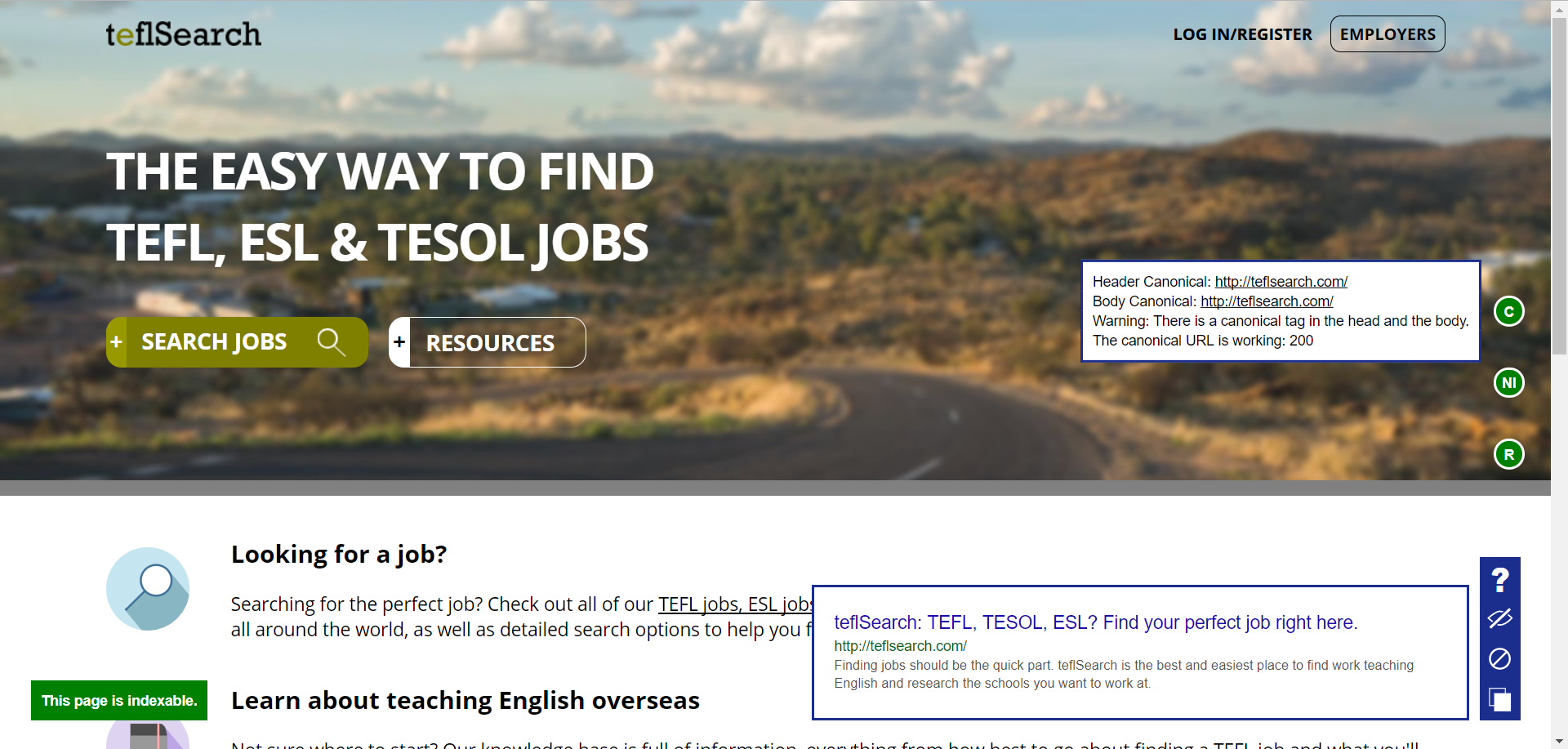
Google Rendered Snippet
This part is really quite simple. The title and meta description are both pulled from the rendered page as mentioned above and then inserted into a Google snippet.
Indexation
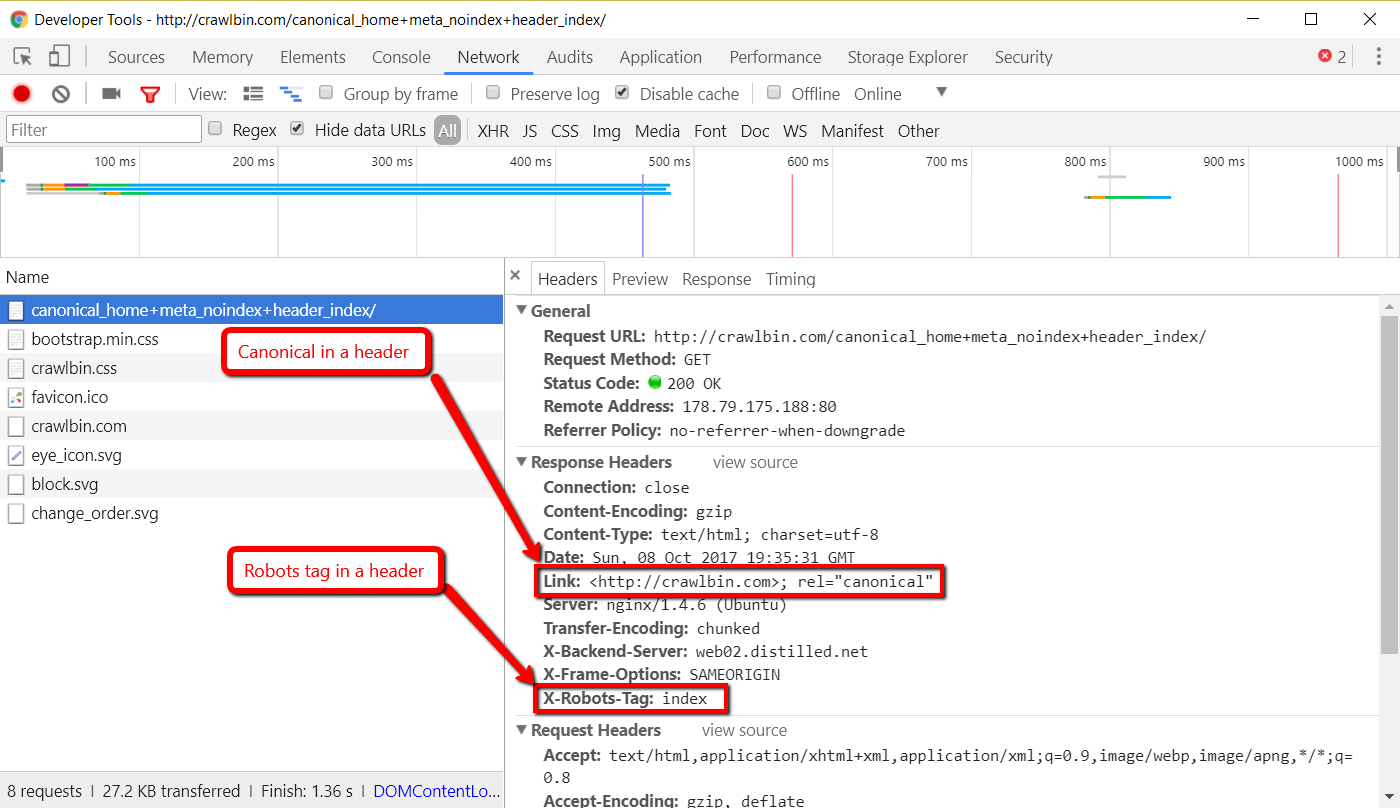
The extension monitors all page requests being made by the browser by listening with chrome.webRequest.onCompleted.addListener. This is important because it allows the extension to get headers for any requests made and pass them down to the script which runs on the page.
Canonical
The on-page script, then extracts the canonical from the page and the headers it has been given (if it exists).
Once it has the canonical, it then immediately makes a HEAD request to the canonical URL (if it's relative or absolute) to check the status code.
The extension then goes off and works out the page's index status as set by the canonical.
Robots tag
The on-page script, extracts any robots tag from the page and the headers it has been given (if it exists).
At this point it will then look at whether the canonical and no-index tag contradict each other, before working out the page's index status as set by the robots tag.
Robots.txt
As soon as you load a page on a website, the extension makes a request to local storage for that websites robots.txt, if one doesn't exist it will then attempt to download it.
It will attempt to get a sub-domain specific robots.txt before resorting to the domain level one, if no sub-domain robots.txt exists.
If no robots.txt exists, it won't continue to try and download it, it will instead cache a message that says no robots is stored. (Which means that you'll need to clear the cache, if a robots.txt was then to be uploaded.)
Once it has a robots.txt will then process it and match the current URL to the robots.txt to check if it's blocked.
I've seen mixed evidence from my own experiments about the No-index tag being respected so currently it will ignore them.
Final page status
Once it has all these pieces of information, it will then calculate the overall indexation status of the page. (2 caveats listed in the first section.)
Patch Notes
Version 0.71
- Fixed small console log errors.
Version 0.7
- Added in links back to documentation for errors and warnings.
- Moved storage of robots.txt to local storage to prevent extension from locking up if it hits sync storage limit.
- Extension now makes HEAD requests to canonical URL to check status code.
Understanding Errors
If you're new to SEO it might be helpful to have a little explanation about these errors:
Error: The canonical is returning an error: 4/5XX
This error is returned when the canonical URL returns a 4xx or 5xx status code.
The canonical URL essentially says, this is the preferred URL for this page. But in this case the URL you've chosen doesn't work.
So which URL does it index? It might just ignore your canonical. It might try the other URL several times to see if the error disappears and then use that. It's not clear which page will be indexed to the extension.
Error: There are multiple canonical tags on the page with different values.
This error is returned when there are multiple canonical tags on the page with different values. For example, suppose your page http://example.com/product/ contained both of the following tags.
<link rel="canonical" href="http://example.com/product/" />
<link rel="canonical" href="http://example.com/product/?sale=no" />The canonical URL essentially says, this is the preferred URL for this page and so in this case it makes no sense. You can't have two preferred URLs for a page, you need to pick one and remove the other.
Because of this the extension can't be sure if the page is indexable.
Error: A canonical should be relative or full url with protocol.
Example URL:
-
https://www.example.com/page- Procotol -
https:// - Host -
www.example.com - Domain -
example.com - Path -
/page
- Procotol -
This error is returned when there is a canonical on your page, which isn't an absolute or relative URL:
- Absolute URL -
https://www.example.com/page - Relative URL -
/page - Incorrect URL -
//www.example.com/page - Incorrect URL -
www.example.com/page
In 2, the protocol and host will be taken from the current protocol and host of the website.
So if you're on https://www.example.com/page?gclid=123, and your canonical is /page/ then Google will complete it to https://www.example.com/page.
But in 3 & 4 you've completed part of the URL, which confuses Google about what URL it should use. Google might complete it correctly, or it might not depending on your website setup, so the extension can't be 100% sure that the page is indexable.
Error: The canonical in the body and head do not have the same value.
This error is returned when the canonical sent in the page header isn't the same as the canonical in the head.
Confused about the difference between headers and head? Read this then jump back up.
The canonical URL essentially says, this is the preferred URL for this page and so in this case it makes no sense. You can't have two preferred URLs for a page, you need to pick one and remove the other
Because of this the extension can't be sure if the page is indexable.
Error: There are two contradictory robots tags on the page.
This error is returned when there are two robots tags: on the page which are saying the opposite of each other. A robots tag specifies if the page is indexable
For example:
<meta name="robots" content="noindex" /> <meta name="robots" content="index" />Because of this the extension can't be sure if the page is indexable. You will need to pick one of them.
Error: There is a robots tag on the page and in the header: different values.
This error is returned when there are two robots tags: one in the head and one in a header, saying different things. A robots tag specifies if the page is indexable.
Confused about the difference between headers and head? Read this then jump back up.
For example the extension may have found this:
On page -- <meta name="robots" content="index" /> Header -- X-Robots-Tag:
noindexBecause of this the extension can't be sure if the page is indexable. You will need to pick one of them.
Understanding Warnings
Warning: This page has a noindex and a non-self canonical tag.
This warning is returned when the canonical tag on the page points to a non-self URL and the page has a noindex value from a robots tag.
This is a warning, not an error, because there are two possible scenarios:
- If the URL the canonical is pointing to is no-indexed - Not an issue.
- If the URL the canonical is pointing to is indexable - An issue.
If the canonical URL is indexable, but the current page is no-indexed then you're giving Google two different signals.
- Current page: I am not-indexable. The true version of this URL is the canonical URL.
- Canonical URL: I am indexable.
The current page is saying the canonical URL shouldn't be indexable and the canonical URL is saying it should be.
In the second scenario, you need to pick one, either the canonical or the no-index.
Warning: There is a robots tag in the page and the header: same values.
This warning is returned when there is a robots tag in the head and a robots header saying the same piece of information.
Confused about the difference between headers and head? Read this then jump back up.
For example the extension may have found this:
On page -- <meta name="robots" content="noindex" />
Header -- X-Robots-Tag: noindexHaving the same directive in two different places, means you can change one and forget to the change the other, which is why this returns a warning.
Warning: Can't find a robots.txt file.
This warning is returned when the extension can't download a robots.txt for this domain.
It's generally good practice to have a robots.txt file to tell search engines what they can and can't crawl.
Warning: The canonical URL is redirecting: 3XX
This warning is returned when the canonical URL is returning a 3xx status code.
The canonical URL essentially says, this is the preferred URL for this page. You can think of it sort of like a redirect, but only for search engines.
In the case that the canonical URL redirects, you're essentially creating a redirect chain for a search engine, where it will have to go multiple hops to reach the true canonical URL. This will take up crawl budget and in theory burn some link equity.
You should change the canonical so it points to a 200 URL.
Warning: The canonical on this page isn't an absolute or relative URL, so can't be loaded.
This warning will be loaded in tandem with: Error: A canonical should be relative or full url with protocol.
The extension throws an additional warning in this case, notifying you that because of this error, the canonical hasn't been loaded to check the status code of it, so you won't know if the canonical is a 404 for example.
Warning: There are multiple canonical tags on the page with the same value.
This warning is returned when there are multiple canonical tags on the page, with the same value.
For example the extension may have found:
<link rel="canonical" href="http://example.com/product/" />
<link rel="canonical" href="http://example.com/product/" />Having the same directive in two different places, means you can change one and forget to the change the other, which is why this returns a warning.
Warning: There is a canonical tag on the page and in a header with the same value.
This warning is returned when there is a canonical tag on the page and in a header with the same value.
Confused about the difference between headers and head? Read this then jump back up.
For example the extension may have found:
On Page -- <link rel="canonical" href="http://example.com/product/" /> Header --
Link: <http://example.com/product/>; rel="canonical"Having the same directive in two different places, means you can change one and forget to the change the other, which is why this returns a warning.
Warning: There is no canonical on this page.
This warning is returned when there is no canonical tag on the page.
Having no canonical tag on a URL usually means that no canonical tag will exist on parametered versions of the URL.
This means Google could accidentally index parametered versions of the URL, which is usually un-desirable.
Warning: There are multiple robots tags on the page with the same value.
This warning is returned when there are multiple robots tags on the page with the same value.
For example the extension may have found:
<meta name="robots" content="noindex" />
<meta name="robots" content="noindex" />Having the same directive in two different places, means you can change one and forget to the change the other, which is why this returns a warning.
Difference between Headers & Head
A very simplified HTML page looks like this:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>This is a page</title>
<link rel="canonical" href="http://example.com/page/" />
</head>
<body>
<p>I am a page</p>
</body>
</html>We can see it contains a <head> and a <body> tag. The head tag is where a canonical and robots tag directives should sit.
The headers, are pieces of information sent along with the page you asked for. You can see them being sent with a page in Chrome dev tools.
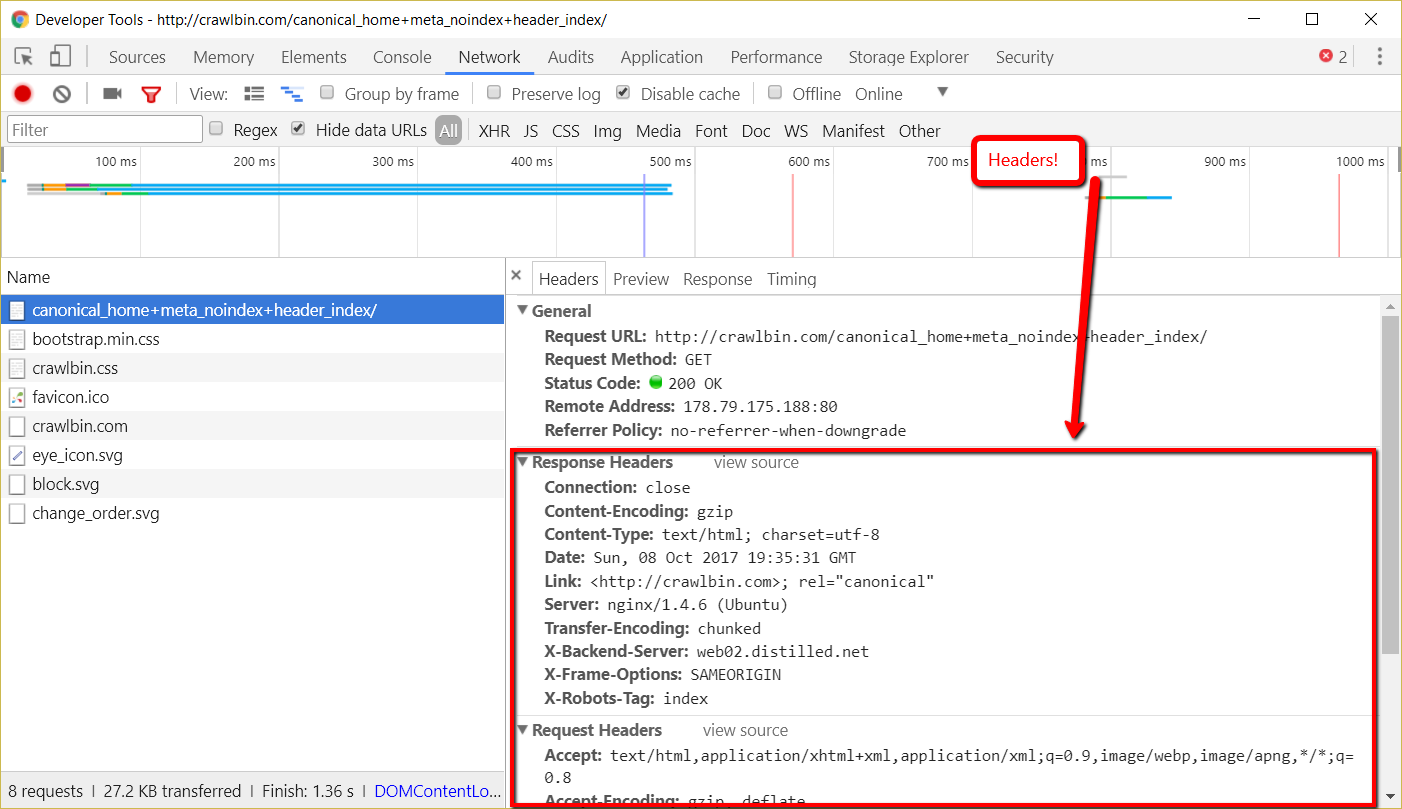
They don't appear anywhere on the page, but they can also contain the equivalent of a canonical tag or a robots tag.